



 科研动态
科研动态 2026-04-26
2026-04-26
在多模态大语言模型(MLLM)推动智能推荐发展的背景下,如何充分融合文本与视觉信息、准确刻画用户兴趣演化,已成为序列推荐研究的重要问题。现有方法在难样本学习和跨模态语义对齐方面仍存在不足,限制了MLLM在推荐场景中的进一步发挥。
近日,重点实验室与新加坡国立大学等单位合作完成论文,研究团队提出HaNoRec框架,通过难度感知重加权策略动态聚焦更具区分难度的训练样本,并设计噪声正则化分布优化目标缓解图文语义错位问题。该项工作由合工大牵头合作完成,被信息检索领域顶级会议SIGIR 2026录用,第一作者为我院2025级博士研究生汪宇,杨永晖博士为通讯作者。SIGIR会议全称为International ACM SIGIR Conference on Research and Development in Information Retrieval,是信息检索领域最具影响力的国际顶级学术会议之一,长期引领搜索、推荐、用户行为建模与智能信息获取等方向的发展,其录用论文代表着当前信息检索领域的前沿研究水平与重要创新成果。
论文简介:
论文标题:Multimodal Large Language Models with Adaptive Preference Optimization for Sequential Recommendation
论文作者:Yu Wang, Yonghui Yang*, Le Wu, Yi Zhang, Fei Liu, Richang Hong.
论文链接:https://arxiv.org/pdf/2511.18740
代码链接:https://github.com/wangyu0627/HaNoRec
论文概述:
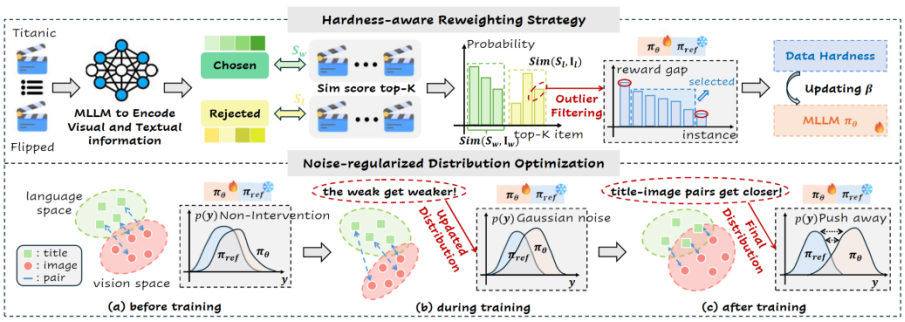
图1 HaNoRec的整体框架图
针对现有序列推荐方法在处理用户历史行为时,往往难以充分利用商品图片、封面等多模态信息,以及传统偏好优化方法容易过度关注“容易区分”的样本、忽视“难区分”样本,并且存在标题与图像语义不一致的问题,本文提出了面向序列推荐的多模态大语言模型框架HaNoRec。该方法一方面设计了难度感知的重加权机制,能够根据样本区分难度动态调整训练重点,使模型更加关注那些更能反映用户细粒度兴趣变化的复杂样本,而不是只学习简单、明显的偏好模式;另一方面,引入噪声正则化分布优化方法,通过对模型输出分布进行平滑约束,增强标题与图像之间的语义对齐能力,减轻多模态信息之间的偏差和误差累积。实验结果表明,HaNoRec在多个公开数据集上均稳定优于现有方法,尤其在排序准确性和推荐相关性方面表现突出,说明其能够更有效地理解用户动态兴趣,并提升多模态序列推荐的整体性能。
SIGIR是数据挖掘领域顶级国际学术会议(CCFA类)。本届 SIGIR 共收到了1271份投稿,其中234篇投稿被接收,中稿率18.4%,体现了入选论文较高的学术水平和国际认可度。
情感计算与先进智能机器安徽省重点实验室
2026年4月26日
 安徽省合肥市蜀山区丹霞路485号(合肥工业大学翡翠湖校区)
安徽省合肥市蜀山区丹霞路485号(合肥工业大学翡翠湖校区) aflab_hfut@163.com
aflab_hfut@163.com