



 科研动态
科研动态 2025-11-15
2025-11-15
近日,中国计算机学会(CCF)推荐的 A 类国际学术会议 —— 第40届人工智能促进会年会(AAAI 2026)论文接收结果正式揭晓。本实验室师生凭借扎实的研究积累与创新突破,多篇高水平学术论文成功入选,涵盖人工智能多个前沿研究方向,彰显了学校在该领域的雄厚科研实力与国际学术影响力。
AAAI会议全称为Association for the Advancement of Artificial Intelligence Annual Conference,是人工智能领域历史最悠久、涵盖范围最广泛的国际顶级学术会议之一,与 NeurIPS、ICML 等并列为全球AI研究的核心交流平台,其录用论文代表着当前人工智能领域的前沿发展方向与高水平研究成果。
论文简介
Main Track
论文题目:
Multi-Value Alignment for LLMs via Value Decorrelation and Extrapolation(oral)
论文作者:
许鹤飞(博士生),吴乐,程晨,刘昊
通讯作者:吴乐
论文概述:
本文提出了一种新的多元价值观对齐框架MVA,用于解决大型语言模型在同时优化多个、可能相互冲突的人类价值观(如有用性、安全性、诚实性)时出现的性能退化与权衡不当问题。现有方法如RLHF、DPO在多目标情境下易出现参数干扰,导致不同价值观间互相削弱。MVA通过两个核心机制来应对这一挑战:其一是Value Decorrelation Training,在对每个价值观进行偏好优化时引入互信息约束,利用Hilbert-Schmidt独立性准则(HSIC)最小化不同价值观向量间的统计依赖,从而减少梯度冲突;其二是Value Combination Extrapolation,通过线性外推和Pareto排序在去相关的参数空间中高效探索帕累托前沿,生成一组具有多样化价值观偏好的模型。实验结果表明,MVA在Anthropic-HH与BeaverTails等多价值观数据集上显著优于DPO、SOUP、MODPO等主流方法,能够在帮助性与安全性等人类价值观之间实现更优的平衡。总体而言,MVA提供了一种可扩展、稳定且可组合的多元价值观对齐范式,为多元化的LLM价值观建模提供了新的研究思路。
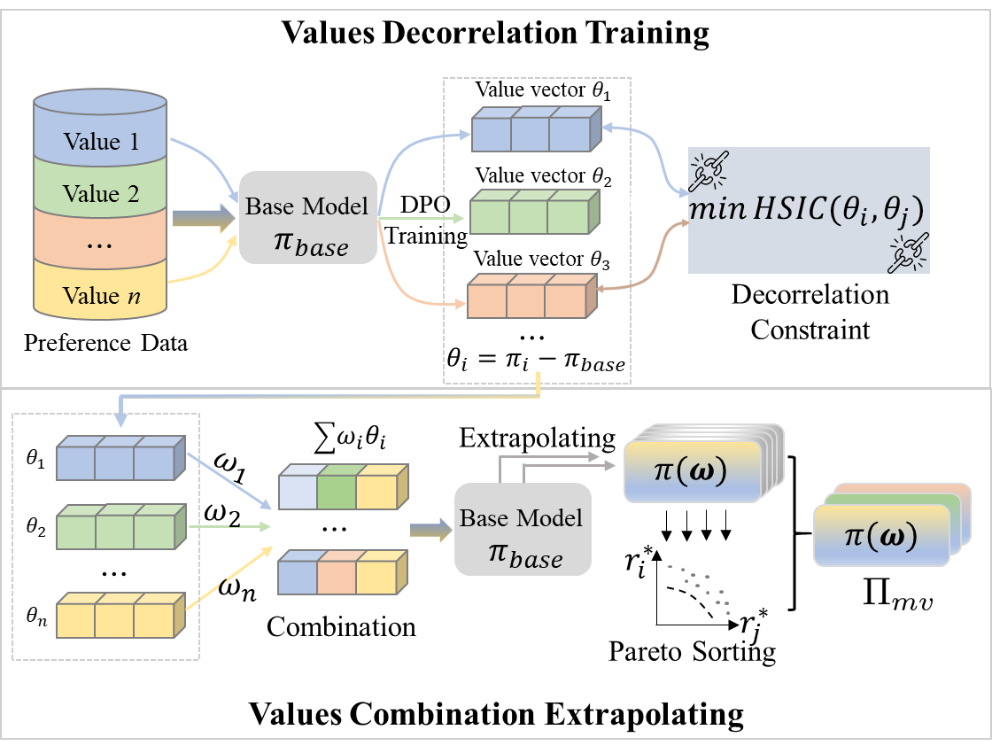
图1 大模型多元价值观对齐框架MVA
论文题目:
RecCocktail: A Generalizable and Efficient Framework for LLM-Based Recommendation (Oral)
作者:
侯旻,白晨希,吴乐,刘昊,张凯,刘卫文,洪日昌,唐睿明,汪萌
通讯作者:吴乐
论文概述:
大语言模型(LLMs)近年来取得了显著进展,这得益于其卓越的泛化能力与丰富的世界知识。为了充分发挥 LLM 在推荐系统中的潜力,现有研究主要集中于两类主流范式。第一类范式通过构建多领域或多任务的指令数据来实现可泛化的推荐,使 LLM 能够对齐通用推荐知识,并有效应对冷启动场景;第二类范式则专注于优化特定领域的推荐任务,以提升在热启动场景下的推荐性能。尽管以往研究通常将这两种范式分开处理,我们认为它们具有天然的互补性,若能加以融合,将进一步提升模型的整体表现。基于此,本文提出了一种兼具泛化性与高效性的 LLM 推荐框架——RecCocktail。该方法首先利用领域通用的推荐指令数据,对 LLM 进行微调,训练得到一个与推荐知识对齐的“基酒”(base spirit)LoRA 模块;随后,根据具体领域的用户行为,构建对应的领域特定“配料”(ingredient)LoRA 模块。在此基础上,我们设计了一种基于熵的自适应融合方法,在权重空间中灵活地混合“基酒”与“配料”,实现通用推荐知识与领域特定推荐知识的有机结合。值得强调的是,RecCocktail 在推理阶段无需增加额外的时间或空间开销,同时兼具两种范式的优势。该框架高效且灵活,具备即插即用的特性:“基酒”LoRA 模块仅需训练一次,而各领域的“配料”模块则可通过轻量级微调快速融合。在多个数据集上的大量实验结果表明,无论在冷启动还是热启动推荐场景中,RecCocktail 都展现出卓越的性能与良好的泛化能力。
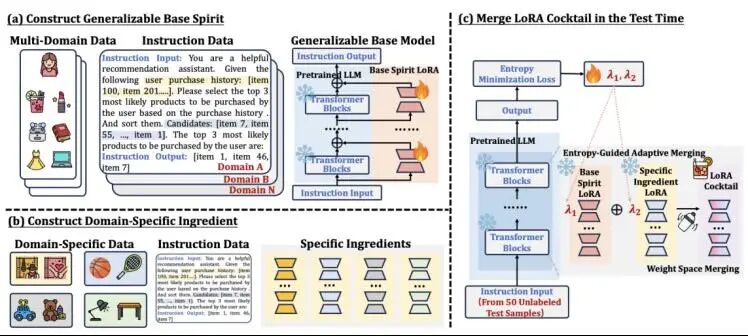
论文题目:
LoRA in LoRA: Towards Parameter-Efficient Architecture Expansion for Continual Visual Instruction Tuning(Oral)
作者:
车畅 (博士生),王子奇,杨鹏万,王琦, 马绘,时增林
通讯作者:时增林
论文概述:
持续视觉指令微调(Continual Visual Instruction Tuning, CVIT)使多模态大语言模型(Multimodal Large Language Models, MLLMs)能够随着时间的推移逐步学习新的任务。然而,这一过程面临灾难性遗忘的挑战,即模型在适应新任务时,其在先前任务上的性能会显著下降。一种常见的缓解遗忘的方法是结构扩展,即为每个任务引入特定的模块以减少任务间的干扰。然而,现有方法通常为每个任务扩展整个层,这导致参数开销巨大、可扩展性差等问题。为了解决这些问题,我们提出了 LoRA in LoRA(LiLoRA),一种专为 MLLM 中的 CVIT 设计的高效架构扩展方法。LiLoRA 通过在任务间共享 LoRA 矩阵 A 来减少冗余,对矩阵 B 进行额外的低秩分解以最小化任务特定参数,并引入基于余弦相似度的稳定性正则项,以在时间维度上保持共享表示的一致性。在多样化的 CVIT 基准上进行的大量实验表明,LiLoRA 在持续的任务学习中表现出显著优于现有方法的性能,同时在参数效率方面也有大幅提升。
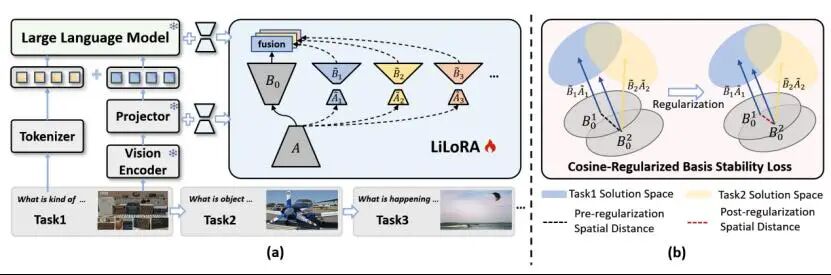
论文题目:
Bidirectional Counterfactual Distillation for Review-Based Recommendation
作者:
桑胜(博士生), 李书杰, 李帅洋, 刘康, 李腾, 贾伟, 郭丹, 薛峰
通讯作者:薛峰
论文概述:
基于评论的推荐方法通常整合多种行为,包括交互、评论和评分,以建模用户偏好。然而,我们认为这些技术在跨行为知识传递过程中存在评级分布偏差污染和特征同质化问题。为了解决这些问题,我们提出了一种新的双向反事实蒸馏(BiCoD)框架。BiCoD 首先设计了一个对抗性反事实蒸馏模块,用于抑制非均匀评分分布对蒸馏过程的影响,从而防止偏差污染用户在不同行为中的真实偏好表示。随后,我们提出一种阶段感知的双向蒸馏策略,以增强行为特征的区分性,促进行为特定偏好的有效学习。基于五个真实数据集的大量实验验证了所提框架的有效性和优越性。
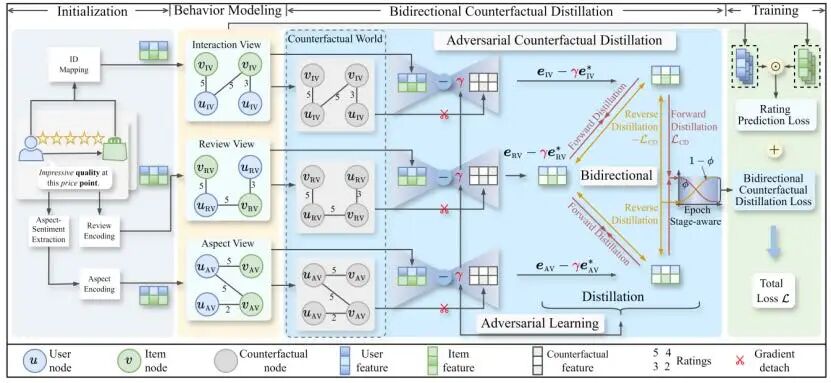
论文题目:
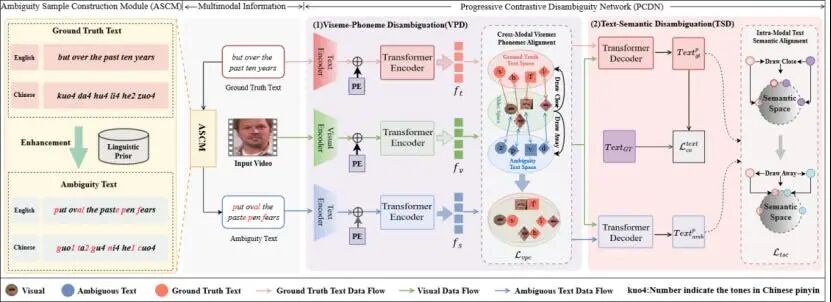
LinProVSR: Linguistics-Knowledge Guided Progressive Disambiguation Network for Visual Speech Recognition
作者:
薛峰,祝保朝,贾伟,李书杰,李雨,张津睿,唐申庚,郭丹
通讯作者:
薛峰
论文概述:
语音识别(VSR),通常称为唇读,通过分析唇部的视觉特征来识别对应文本。由于唇部运动的细微性,其识别比其他动作识别任务要困难得多。现有的VSR模型在处理发音相似的音素时面临音素模糊问题——多个音素共享相似的唇形特征,导致唇读准确率显著下降。为解决这一问题,本研究提出了一种面向视觉语音识别的语言学知识引导渐进消歧网络框架(LinProVSR)。首先,基于语言学知识构建一个模糊样本集,为模型训练提供监督信号。然后,设计了渐进对比消歧网络(PCDN),通过编码阶段的唇形-音素对比消歧和解码阶段的文本对比消歧,逐步增强模型捕捉相似音素对应细微唇形差异的能力。此外,我们率先提出了专门用于评估语音模糊文本识别的模糊词错误率(AWER)指标,并在多个公开数据集上验证了所提方法的有效性,尤其在区分视觉上相似的音素方面取得了显著突破。
论文题目:
Anchor Watermark: Robust Attribution for Diffusion-based Text-to-Audio Model (Oral)
作者:
荣先进(博士)、胡东辉
通讯作者:胡东辉
论文概述:
随着基于扩散模型的文本生成音频(Text-to-Audio, TTA)技术(如 AudioLDM、Tango、MusicLM 等)的迅速发展,生成式音频应用正加速商业化。然而,这一趋势也引发了严峻的伦理与安全问题。针对现有音频水印方法鲁棒性不足、降低生成质量及需额外训练等缺陷,本研究提出了一种基于潜空间锚点的反演优化框架。该方法在扩散模型的初始潜向量中嵌入水印(即“锚点”),并通过反演过程实现水印提取。为减轻反演过程中的误差累积,研究进一步利用扩散模型的时间一致性与分布相似性,将水印验证建模为时间序列优化问题,并引入 Soft Dynamic Time Warping(Soft-DTW)损失函数,以实现灵活的时间对齐与高鲁棒性归属判定。实验结果表明,本方法在无需重新训练模型的前提下,能够在多种攻击(如压缩、加噪、重采样等)下保持约99%的检测准确率。在 AudioLDM、Tango 等主流模型以及 AudioCaps 等数据集上的实验证实了该方法的通用性与稳定性。本研究为扩散式音频生成模型提供了一种高鲁棒、无损失、训练无关的音频水印方案,对防止模型滥用与追踪生成来源具有重要的理论与实践意义。

论文题目:
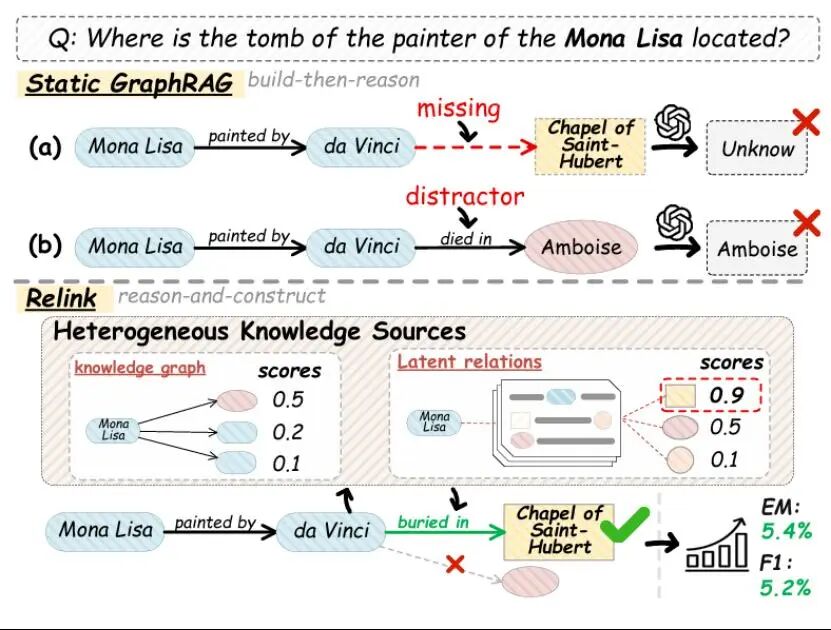
Relink: Constructing Query-Driven Evidence Graph On-the-Fly for GraphRAG
作者:
黄满宗(博士生)、卜晨阳、卓兴锐、何逸、吴信东
论文概述:
现有的GraphRAG方法通常采用“先构建图,再进行推理”的范式,即先从语料中构建一个静态知识图谱,然后在其中执行多跳推理。然而,静态知识图谱先天存在不完整性,部分必要关系缺失会导致推理链条被截断;同时,知识图谱中还存在大量与主题相关但与答案无关的干扰信息误导推理方向。为此,本文提出Relink,采用“先推理、再构建”的范式,动态按查询需求构建证据链。Relink首先以一个高精度但可能稀疏的知识图谱作为推理骨架,同时从文本语料中构建高召回的潜在关系池。在推理过程中,对来自显式KG与潜在关系的候选边进行统一的、面向问题的排序评估,选择最有助于回答问题的关系;当遇到断链时,系统会调用LLM按需实例化潜在关系,从而实现动态补链与去噪。这种机制使Relink 能针对每个查询生成紧凑、清晰且高可信的证据图。在五个开放域多跳QA数据集上,相比领先基线平均EM提升5.4%,F1提升5.2%。
论文题目:
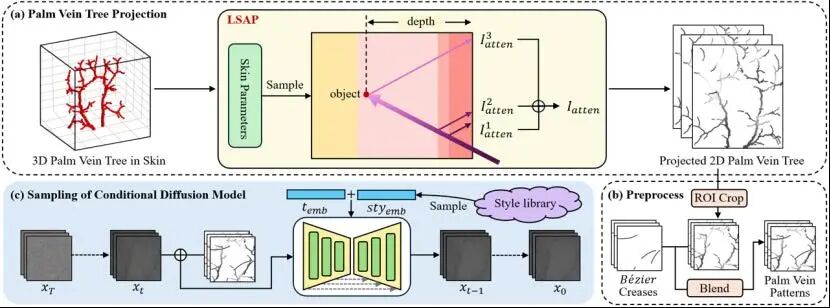
LSAP-PV: High-Fidelity Palm Vein Image Synthesis via Layered Spectral Absorption Projection-Guided Diffusion Model (AAAI26-oral)
作者:
尚胜,赵成龙,张睿欣,金建龙,张菁芸,王军,赵洋,丁守鸿,贾伟
Jingyun Zhang, Jun Wang
通讯作者:丁守鸿,贾伟
论文概述:
现有的掌静脉图像生成方法忽视了身份与静脉模式间的生物物理关系,尤其在模拟身份特定的静脉对比度方面存在不足。为此,我们提出一种新颖的生物物理学驱动的合成方法。该方法通过成熟的建模技术构建三维手掌血管树,之后提出一种投影模型将三维结构映射至二维空间以生成掌静脉模式。该投影模型基于皮肤光谱吸收特性,采用分层积分法模拟光线穿透皮肤的自然衰减过程。针对不同身份,我们通过采样不同的皮肤参数来实现不同程度的衰减效果,有效模拟了跨身份静脉对比度的自然差异。此外,我们引入条件扩散模型,将投影得到的静脉模式作为身份条件来生成掌静脉图像。实验结果表明,该方法优于现有的方法,在质量评估和识别效果上取得了更优的结果。
论文题目:
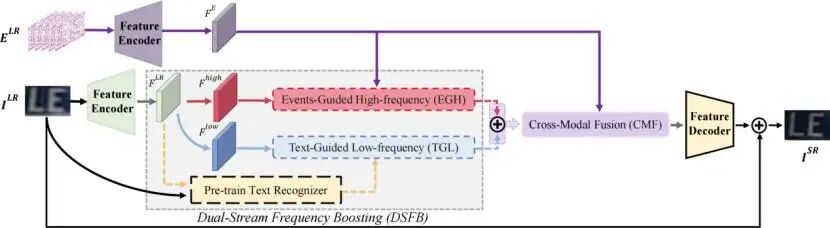
Event-Guided Scene Text Image Super-Resolution
作者:
祁子涵,肖泽宇,赵豪宜,赵洋,薛峰,贾伟
通讯作者:肖泽宇,贾伟
论文概述:
本文提出了 EvTSR,一种新颖的事件驱动场景文本超分辨率框架。场景文本图像超分辨率(TSR)旨在从低分辨率输入中恢复高分辨率文本,以增强文本清晰度。然而,在弱光和高速运动等恶劣条件下,传统方法往往难以保持文本笔画和边缘等精细细节。
EvTSR 首次将事件数据整合到 TSR 任务中,利用其捕获运动和强度变化的优势来恢复丢失的细节。EvTSR 的核心是双流频率增强 (DSFB) 机制,它将图像特征分离为高频和低频分量。高频细节(如边缘和笔画)通过事件引导高频(EGH)模块利用事件数据进行增强;而负责全局结构的低频分量,则通过文本引导低频(TGL)模块利用预训练的文本识别器进行细化,确保文本的连贯性。此外,跨模态融合(CMF)模块有效对齐事件和图像特征,实现了鲁棒的信息融合。广泛的实验证明,EvTSR 在文本细节恢复、清晰度和识别准确性方面均优于现有方法,为解决挑战性场景中的 TSR 问题提供了有效方案。
论文题目:
A Closer Look at Knowledge Distillation in Spiking Neural Network Training
作者:
刘旭(博士),夏娜,周金星,徐静远,郭丹
第一作者:刘旭
通讯作者:夏娜,郭丹
发表会议:AAAI 2026
论文概述:
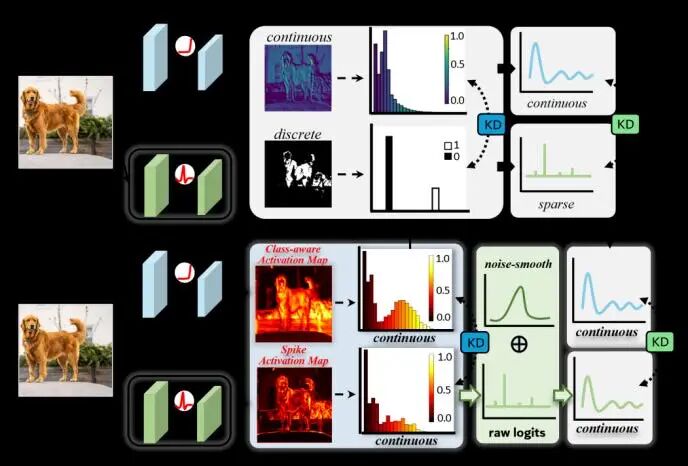
脉冲神经网络(Spiking Neural Network, SNN)作为一类模拟生物神经元工作机制的节能型神经网络,是实现高效低功耗人工智能的重要方向。最近的做工作大多围绕着知识蒸馏的方式训练SNN,将传统人工神经网络(Artificial Neural Network, ANN)当作教师,SNN当作学生,对其两者的原始特征或logits,然而忽视了二者在输出分布上的本质差异:ANN输出连续,而SNN输出稀疏且离散,导致知识迁移效果受限。为此,我们提出了两种创新的蒸馏策略:一是显著性激活图蒸馏(Saliency-scaled Activation Map Distillation,SAMD),通过引导SNN学习教师ANN生成的类别感知显著性激活图,既能增强语义对齐有能缓解两者的分布差距;二是噪声平滑logits蒸馏(Noise-smoothed Logits Distillation, NLD),利用高斯噪声平滑SNN的稀疏logits,使其更易与ANN的连续输出对齐。实验表明,所提的CKDSNN方法有效提升了SNN的训练效果与泛化能力。
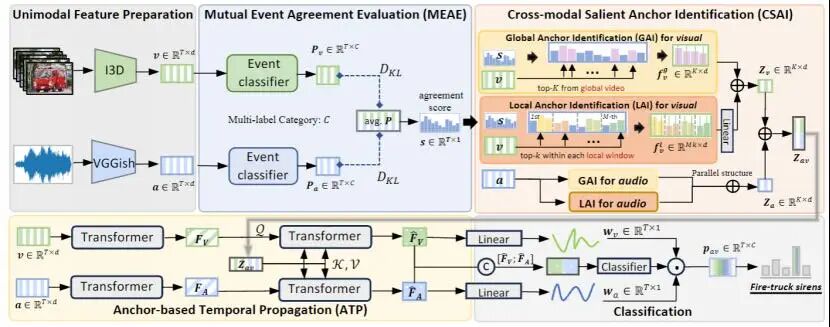
论文标题:
CLASP: Cross-modal Salient Anchor-based Semantic Propagation for Weakly-supervised Dense Audio-Visual Event Localization
作者:
周金星(博士),周子恒,周杨浩,毛宇昕,段章领,郭丹
通讯作者:郭丹
论文概述:
在长视频音视频理解领域,手动标注细粒度事件时序边界成本极高,成为技术落地的关键障碍。本文创新性提出弱监督密集音视频事件定位(W-DAVEL)任务,并提出了用于该任务的全新框架CLASP。该框架仅需视频级事件标签,即可实现音频视频模态共现事件的精准时序定位。CLASP 以跨模态显著锚点为核心,通过三大模块高效完成定位:MEAE 模块量化音视频事件预测一致性,CSAI 模块结合全局与局部窗口机制精准识别锚点,ATP 模块将锚点的强语义传播至全时序特征。这种设计既保证了定位精度,又大幅提升效率。实验验证显示,CLASP 在 UnAV-100 和 ActivityNet1.3 两大数据集上均展现出优异性能。其不仅解决了长视频弱监督定位的核心痛点,更在多场景下展现出优异泛化性,为智能监控、视频检索等实际场景提供了高效可靠的技术支撑,推动音视频跨模态学习迈向实用化新阶段。
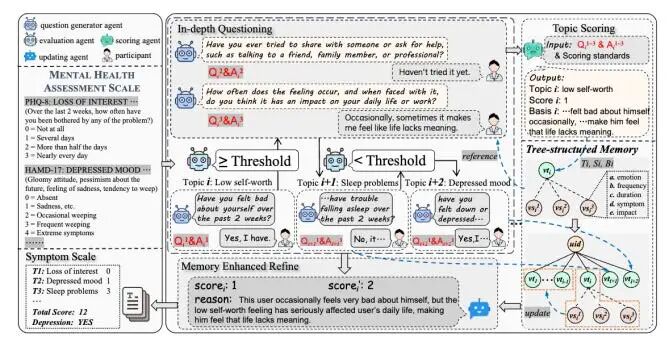
论文题目:AgentMental:An Interactive Multi-Agent Framework for Explainable and Adaptive Mental Health Assessment
作者:
胡金鹏、王澳、谢倩倩、马绘、李卓、郭丹
通讯作者:郭丹
论文概述:
心理健康评估对于早期干预和有效治疗至关重要,但传统依赖临床医生的评估方式受限于专业人员短缺。现有方法大多依赖静态文本分析,难以捕捉在动态交互与迭代提问过程中产生的更深层次心理信息。为此,我们提出了一种用于心理健康评估的多智能体框架,通过模拟临床医患对话实现自动化评估。该框架包含提问、回答充分性评估、打分与动态更新等多个专职智能体。其中,我们设计了一种自适应提问机制:评估智能体根据用户回答的充分性自动判断是否生成针对性追问,以弥补模糊或缺失的信息。此外,框架引入树状记忆结构,以根节点记录用户基本信息,子节点(如主题、陈述)则根据症状类别和对话轮次组织关键信息。该记忆在交互过程中动态更新,从而减少冗余提问,增强信息提取与语境追踪能力。在心理评估数据集上的实验结果验证了其有效性与应用潜力。
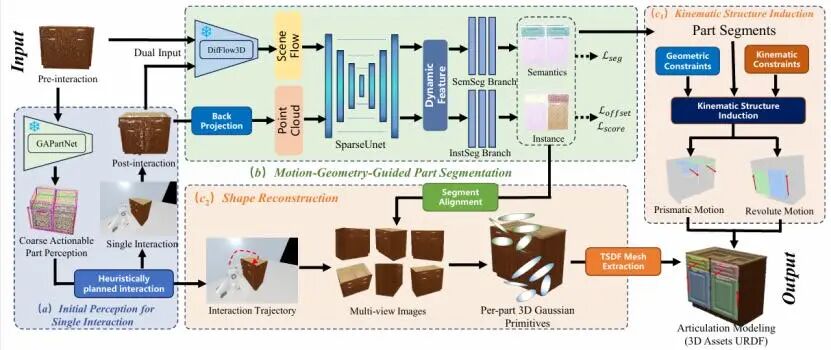
论文题目:
SIAM: Towards Generalizable Articulated Object Modeling via Single Robot-Object Interaction
作者:
刘玉研(硕士生),张力,吴迪,张岩(本科生),黄安然,王志,刘浏,郭丹
通讯作者:刘浏
论文概述:
关节体建模通过连通的刚体构建三维对象的结构化表征,统一编码几何形状、部件分割、运动关系及物理属性,为机器人感知、抓取与交互任务提供关键支撑。然而现有方法多依赖缺乏真实纹理与物理特性的CAD模型,或采用成本高昂的人工扫描方式,限制了实际应用。SAGCI系统虽引入交互感知范式,通过动态操作优化关节参数,但仍存在依赖人工先验、未整合运动学约束及生成模型存在几何缺陷等不足。为此,我们提出SIAM框架,通过单次机器人-物体交互实现高效通用建模:首先基于粗粒度部件感知引导交互,通过运动几何分析实现精准部件分割;进而提出融合运动学约束的能量优化方法,提升关节参数估计的物理一致性;最后基于部件高斯建模生成闭合连续的网格模型,显著提升几何质量与仿真适应性。实验在PartNet-Mobility数据集及真实机器人平台上验证了方法的先进性与泛化能力,为部件级机器人操作提供了新途径。
论文题目:
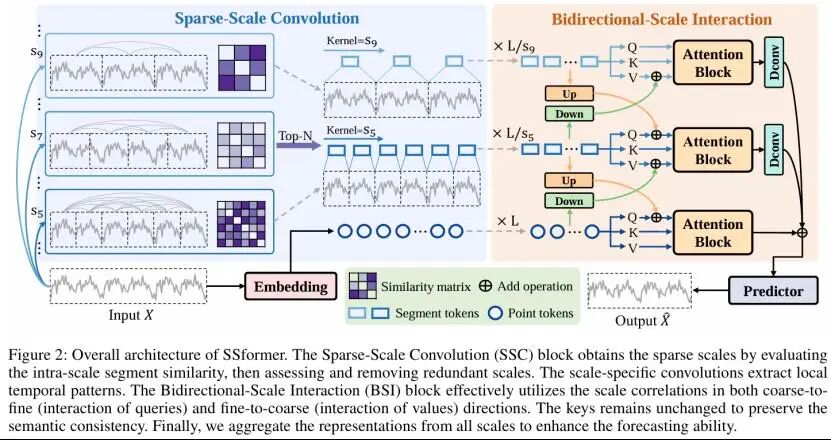
Sparse-Scale Transformer with Bidirectional Awareness for Time Series Forecasting
作者:
刘颖(博士生),刘博,黄晟,罗刚,胡文波,汪萌,洪日昌
通讯作者:刘博
论文概述:
时间序列预测在诸多实际应用中发挥着至关重要的作用,如天气预测和经济规划等。尽管基于Transformer的模型在建模长时依赖方面表现出强大的能力,但如何有效捕获时间序列中内在的多尺度时间动态仍然是一个主要挑战。现有方法通常采用不同大小的时间窗口,但当这些窗口与潜在的时间模式不匹配时,可能会引入噪声或无关的表示,从而导致过拟合问题。本文提出了一种用于时间序列预测的具有双向感知能力的稀疏尺度Transformer以增强时间序列的多尺度建模能力。具体而言,我们设计了一种新颖的稀疏尺度卷积模块,通过评估时间序列在同一尺度内的片段相似性在尺度上施加稀疏性约束,从而获得更有效的表示。同时利用尺度特定的卷积操作来提取局部模式。此外,我们提出了双向尺度交互模块,以建模尺度之间由粗粒度到细粒度和由细粒度到粗粒度的双向相关性。最后,我们通过融合不同尺度的预测结果,充分发挥各尺度间互补的预测能力。
论文题目:
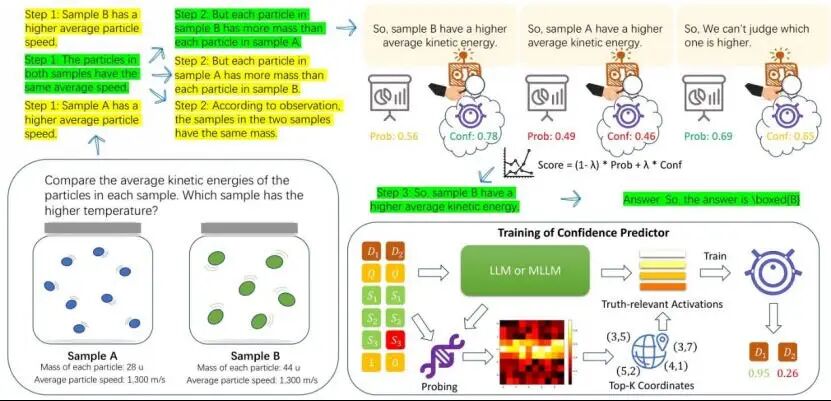
Deep Hidden Cognition Facilitates Reliable Chain-of-Thought Reasoning
作者:
陈紫军,胡文波,洪日昌
通讯作者:胡文波
论文概述:
链式思维(CoT)推理在大语言模型(LLMs)和多模态大语言模型(MLLMs)中均展现出卓越的深度推理能力。然而,其可靠性常因中间步骤的误差累积而受损。本文提出一种新方法,通过利用模型对真实性的内部认知来校准 CoT 推理的准确性。研究发现,在动态、渐进的推理过程中,模型会隐性追踪中间步骤真实性的变化。我们训练了一个置信度预测器,用于量化模型在每个推理步骤对真实性的内部认知,并通过束搜索实现对最合理推理路径的动态选择。实验结果表明,在数学、符号和常识推理任务中,该方法显著优于最先进的基线方法,在单模态和多模态场景下均展现出更优的准确性和可靠性。本研究为提升 CoT 推理的可靠性提供了一条新路径,展现出广泛的应用潜力。
论文题目:
Understanding and Benchmarking the Trustworthiness in Multimodal LLMs for Video Understanding
作者:
王有泽, 陈紫军, 陈若禹, 顾士燊 胡文波, Jiayang Liu, Yinpeng Dong, Hang Su, 朱军, 汪萌, 洪日昌
通讯作者:胡文波
论文概述:
近年来,用于视频理解的多模态大语言模型(videoLLMs)取得了显著进展,其处理复杂时空数据的能力得到大幅提升。然而,事实不准确、有害内容、偏见、幻觉以及隐私风险等挑战,仍影响着这类模型的可靠性。本研究提出了 Trust-videoLLMs—— 首个全面的基准框架,该框架从真实性、鲁棒性、安全性、公平性和隐私性五个关键维度,对 23 个最先进的 videoLLM(5 个商业模型、18 个开源模型)进行评估。
该框架包含 30 项任务,涉及适配视频、合成视频和标注视频,可评估时空风险、时序一致性及跨模态影响。实验结果表明,现有 videoLLM 在动态场景理解、跨模态抗干扰能力以及现实场景风险缓解方面存在显著不足。尽管开源模型在某些情况下表现更优,但专有模型总体可信度更高,不过模型规模扩大并不总能提升性能。
这些发现凸显了提升训练数据多样性和强化多模态对齐的必要性。Trust-videoLLMs 提供了一个可公开获取、可扩展的工具库,用于标准化可信度评估,填补了当前以准确性为核心的基准与对鲁棒性、安全性、公平性及隐私性需求之间的关键空白。

论文题目:
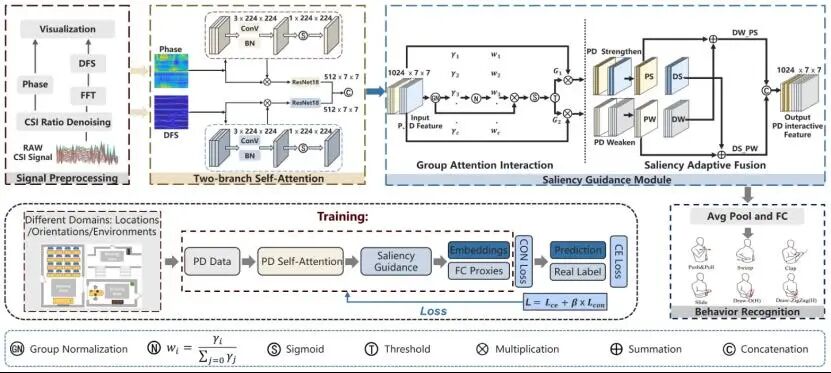
Wi-CBR: Salient-aware Adaptive WiFi Sensing for Cross-domain Behavior Recognition
作者:
张若北(博士生),唐申庚,颜焕,章翔,郭嘉宝
通讯作者: 唐申庚 ,郭嘉宝
论文概述:
当前基于Wi-Fi的跨领域行为识别面临的主要挑战在于领域特定信号对行为变化的显著干扰。现有方法通常将来自多个域的相位信息映射到公共特征空间来缓解此类干扰。我们认为,若利用多普勒频移(DFS)信号对相位特征进行动态补充,可进一步提升模型的泛化能力,不仅有助于探索更丰富的特征空间,还能避免行为语义信息的潜在退化。具体而言,我们提出了一种新颖的跨域行为识别方法——显著感知自适应Wi-Fi感知(Wi-CBR)。该方法构建了一个双分支自注意力机制模块,分别从反映动态路径长度变化的相位信息中提取时序特征,以及从与运动速度相关的DFS信号中提取动力学特征。此外,通过显著性引导模块(Saliency Guidance Module, SGM)利用分组注意力机制挖掘关键行为特征,并采用门控机制优化信息熵,促进特征的有效融合,从而增强显著与非显著行为特征之间的交互。实验结果表明,我们的方法在域内及跨域场景下均表现出更优的性能。本研究展示了将基于建模的先验知识与深度学习相结合,在解决跨域行为识别问题上具有重要潜力。
论文题目:
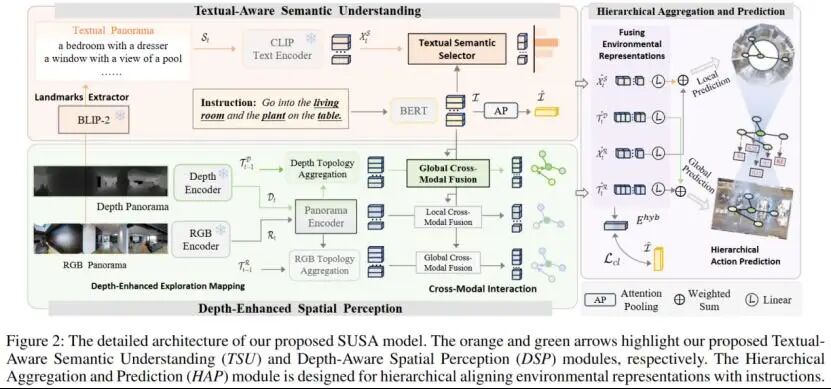
Agent Journey Beyond RGB: Hierarchical Semantic-Spatial Representation
Enrichment for Vision-and-Language Navigation
作者:
张雪松(博士生),徐赟博,李佳,刘若楠,胡珍珍
通讯作者:李佳
论文概述:
视觉与语言导航智能体依据自然语言指令在未知具身环境中进行导航仍然面临困难。本文提出一种层级式的环境语义理解与空间综合感知(SUSA)架构,以促进智能体更好地进行环境语义锚定和空间感知。本文通过生成视图级别的文本语义描述来捕捉细粒度的环境语义用于局部决策,并缓解了指令和环境之间的模态差异。另一方面,本文逐步构建了轨迹级别的环境探索图来增强模型对全局环境布局的理解。最后,对这些混合的语义-空间表征进行分层聚合,以感知互补的环境信息,并采用对比学习将它们与自然语言指令对齐。实验表明,SUSA不仅在三个流行的离散导航任务上表现优异,在连续的VLN任务上也表现出良好的泛化性。同时,得益于提出的部分预训练策略,SUSA依旧轻量且高效。
情感计算与先进智能机器安徽省重点实验室
2025年11月15日
 安徽省合肥市蜀山区丹霞路485号(合肥工业大学翡翠湖校区)
安徽省合肥市蜀山区丹霞路485号(合肥工业大学翡翠湖校区) aflab_hfut@163.com
aflab_hfut@163.com