



 科研动态
科研动态 2025-11-10
2025-11-10
随着多模态大模型的广泛应用,错误与过时知识的低成本快速更新成为行业痛点。现有方法多聚焦语言模型部分,却忽视了视觉信息作为知识核心时的编辑挑战。本重点实验室博士生曾振牵头提出以视觉为导向的细粒度多模态知识编辑方案,构建专属基准并研发创新框架,实现图像局部知识的精准更新,为多模态大模型优化提供全新思路!
近日,全球计算机视觉领域顶级盛会——国际计算机视觉大会(ICCV)公布录用结果,本重点实验室博士生曾振以第一作者身份撰写的论文成功入选。该项成果由合肥工业大学联合中国科学技术大学、合肥综合性国家科学中心人工智能研究院共同完成,本重点实验室时增林教授为通讯作者,彰显了本实验室在多模态大模型领域的科研硬实力。
论文简介:
论文标题:
Visual-Oriented Fine-Grained Knowledge Editing for MultiModal Large Language Models
论文作者:
Zhen Zeng, Leijiang Gu, Xun Yang, Zhangling Duan, Zenglin Shi, Meng Wang.
论文链接:
https://arxiv.org/pdf/2411.12790
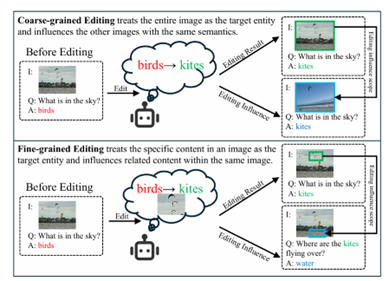
图 1 细粒度视觉知识编辑任务
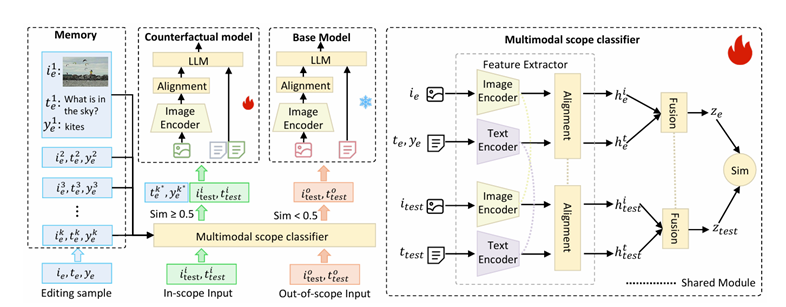
图 2 MSCKE方法框架
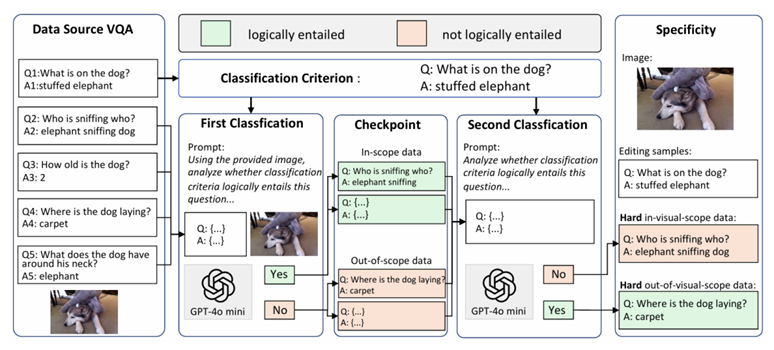
图 3 细粒度视觉知识编辑基准FGVEdit
现有多模态知识编辑工作多为文本导向的粗粒度修改,难以应对多实体交互图像的精准编辑需求。为此,研究团队提出细粒度视觉知识编辑任务,构建了FGVEdit基准用于评估编辑准确性与有效性。针对核心挑战,研发基于多模态范围分类器的知识编辑器(MSCKE),通过整合文本与视觉信息,精准定位并更新图像局部知识,在保证编辑精度的同时不影响无关内容。大量实验验证表明,现有方法难以适配细粒度多模态编辑需求,而 MSCKE 框架展现出显著优势与可扩展性,为该领域发展提供重要支撑。
ICCV是全球计算机视觉领域最具影响力的顶级学术盛会之一,与CVPR和ECCV并称“计算机视觉三大顶会”。ICCV在学术界与产业界均占据核心地位,且被中国计算机学会(CCF)评定为A类会议。
情感计算与先进智能机器安徽省重点实验室
2025年11月10日
 安徽省合肥市蜀山区丹霞路485号(合肥工业大学翡翠湖校区)
安徽省合肥市蜀山区丹霞路485号(合肥工业大学翡翠湖校区) aflab_hfut@163.com
aflab_hfut@163.com