



 科研动态
科研动态 2025-09-23
2025-09-23
让AI看懂照片里的喜怒哀乐已不稀奇,但要读懂一段视频里情绪的起承转合,就像让它看懂一部电影的“内心戏”,挑战巨大。我院师生最新提出的S2D模型,就像一个巧妙的“升级包”,给顶级的“图片表情分析师”装上了“时间洞察镜”,还教会它紧盯眼角、嘴角的关键“微表情”。最亮眼的是,整个升级过程仅需微调不到10%的参数,在多个领域内权威测试基准上,成功刷新了最高纪录(SOTA)!快来一起见证这场人工智能的“读心”风暴吧!
近日,我重点实验室博士研究生陈银的论文《From Static to Dynamic: Adapting Landmark-Aware Image Models for Facial Expression Recognition in Videos》被情感计算领域国际顶级期刊 IEEE Transactions on Affective Computing (TAFFC) 录用。该项工作由我重点实验室洪日昌教授和李佳副教授共同指导完成,陈银同学为第一作者,李佳老师为通讯作者,研究得到了中国科学院计算技术研究所山世光研究员等人的支持与合作。该成果为解决真实场景下动态情感识别数据稀缺、模型训练成本高的核心难题提供了高效、强大的新范式,在多个权威动态表情识别数据集(如DFEW, FERV39K, MAFW)上取得了当前最佳性能。
论文简介
论文标题:
From Static to Dynamic: Adapting Landmark-Aware Image Models for Facial Expression Recognition in Videos
论文作者:
陈银,李佳,山世光,汪萌,洪日昌
论文链接:
https://ieeexplore.ieee.org/abstract/document/10663980
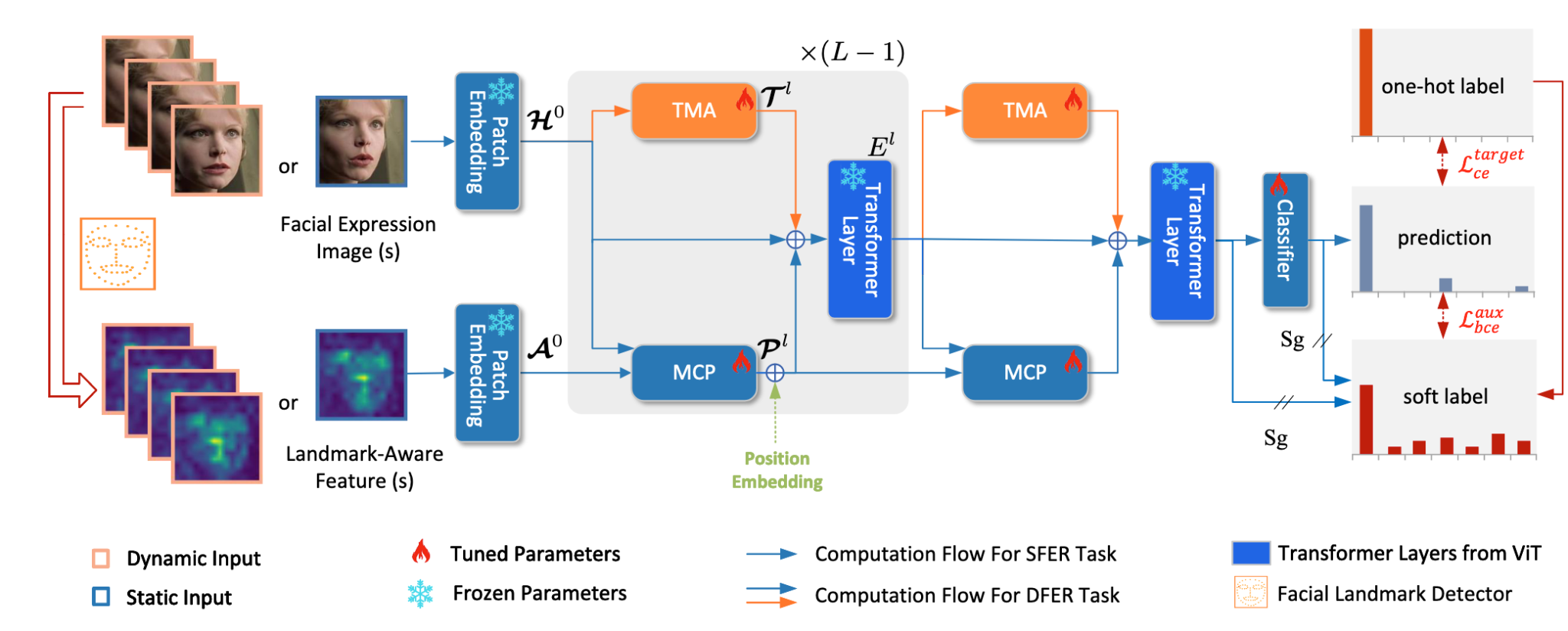
图 1 网络结构图
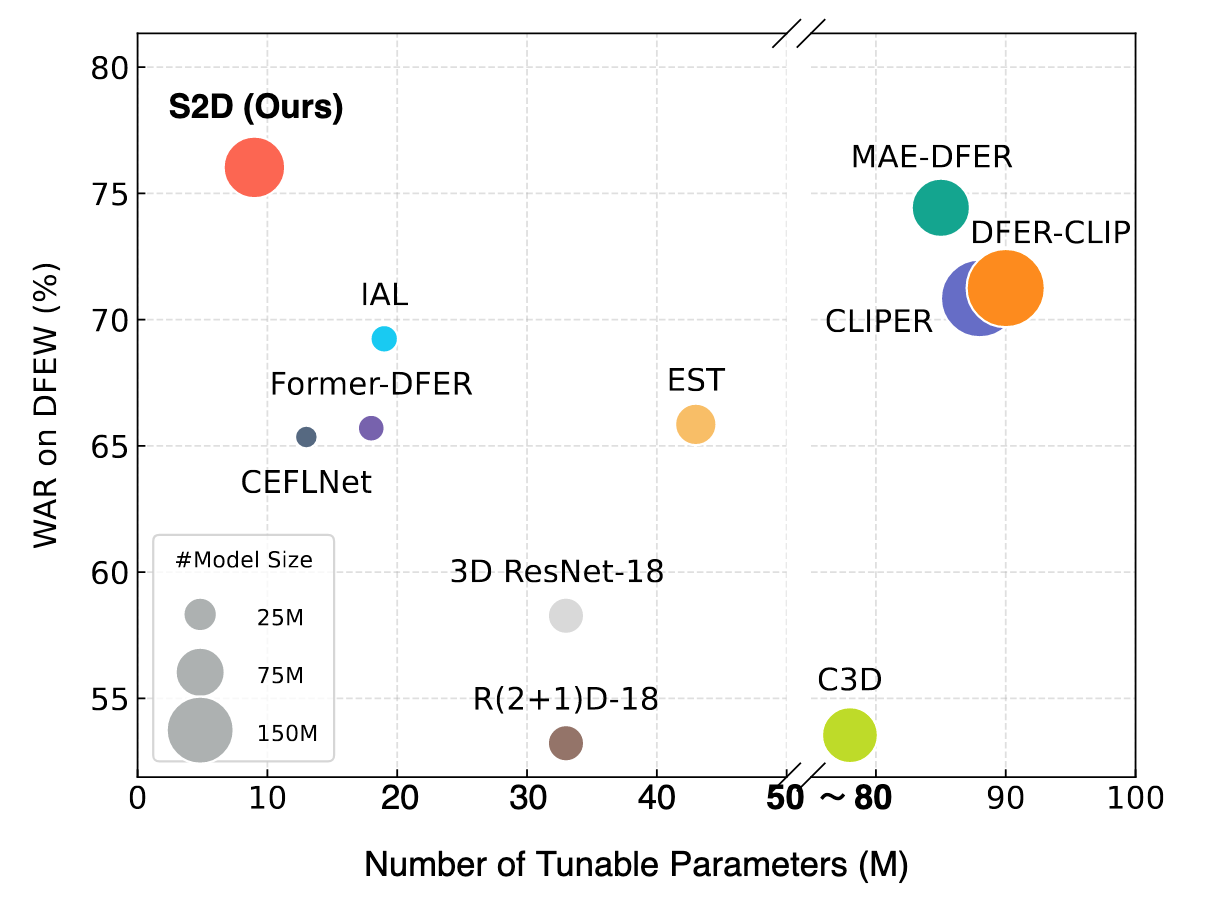
图 2 性能参数对比图
该论文针对真实场景下动态表情识别存在的数据稀缺、模型训练成本高昂等挑战,提出了一种“从静态到动态”的高效模型适配框架S2D (其整体架构如图1所示)。该框架通过将轻量级的“时间建模适配器”(TMAs)插入到预训练的静态图像模型中,并利用面部关键点信息进行特征增强,实现了从静态图像识别到动态视频识别的高效迁移。经过在DFEW、FERV39K等多个国际权威动态表情识别数据集上的实验验证(性能与参数效率对比如图2所示),相较于传统的视频模型训练方法,S2D在仅微调不足10%参数的条件下,性能便全面超越了以往的最佳方法。在核心的DFEW数据集上,模型整体准确率(WAR)相较于此前的最佳监督学习方法提升了6.73%
IEEE Transactions on Affective Computing (TAFFC) 是情感计算领域的顶级国际期刊,由IEEE计算智能学会(Computational Intelligence Society)主办。该期刊为中科院JCR一区Top期刊,是人工智能情感计算与人机交互领域的旗舰级学术期刊,代表了该领域的最高研究水平。
情感计算与先进智能机器安徽省重点实验室
2025年9月23日
 安徽省合肥市蜀山区丹霞路485号(合肥工业大学翡翠湖校区)
安徽省合肥市蜀山区丹霞路485号(合肥工业大学翡翠湖校区) aflab_hfut@163.com
aflab_hfut@163.com