



 科研动态
科研动态 2025-09-19
2025-09-19
视频时序定位是视频理解领域的核心任务之一,旨在根据自然语言或语音查询,精准定位视频中与之语义对应的片段。近年来,随着多模态交互技术的快速发展,视频时序定位在智能视频检索、人机交互、内容理解等应用中展现出巨大潜力。
近日,我重点实验室最新研发的UniSDNet模型,赋予机器人类般的"视频直觉",精准捕捉画面中的时空语义关联。这项突破性技术通过创新的静态-动态协同的视觉感知建模机制,在6大视频基准测试中表现卓越——不仅在ActivityNet数据集上实现了75.85%的片段定位准确率(R@1,IoU=0.3),更以1.56倍的推理速度超越现有最优算法。从智能安防到跨媒体检索,这场视频理解的"认知革命"正开启智能视觉分析新纪元!
2025年8月,人工智能领域顶级期刊《IEEE Transactions on Pattern Analysis and Machine Intelligence》(TPAMI,影响因子20.8)正式发表了我重点实验室2024级博士研究生胡晶晶为第一作者的论文《Unified Static and Dynamic Network: Efficient Temporal Filtering for Video Grounding》。合肥工业大学为第一完成单位,我重点实验室郭丹教授与汪萌教授为通讯作者。
论文简介:
论文标题:
Unified Static and Dynamic Network: Efficient Temporal Filtering for Video Grounding
论文作者:
Jingjing Hu, Dan Guo, Kun Li, Zhan Si, Xun Yang, Xiaojun Chang, Meng Wang
论文链接:
https://ieeexplore.ieee.org/abstract/document/10955430
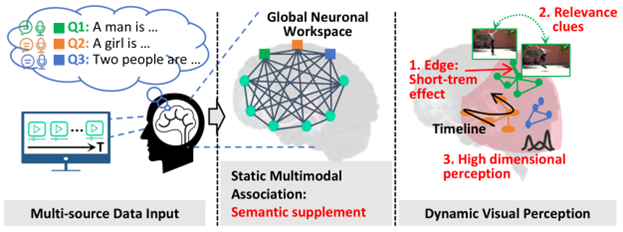
图 1 人类视觉感知机制启发的静态模态关联与动态视觉感知建模方法
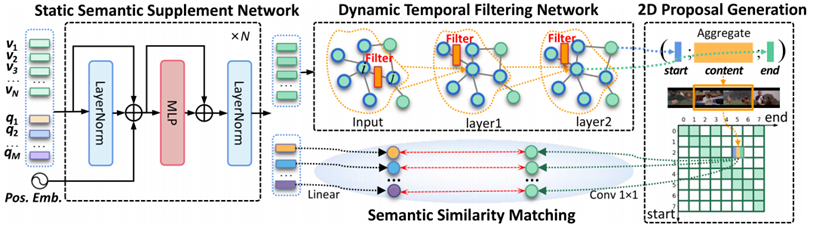
图 2 静态语义关联网络与动态时序过滤网络框架
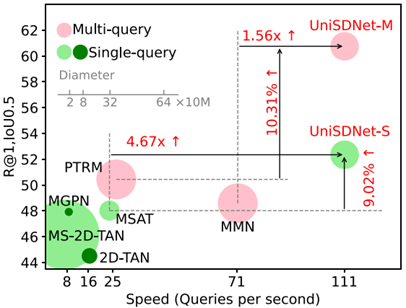
图 3 在ActivityNet数据集上的性能对比结果
该研究受人类视觉感知生物学机制启发,针对视频时序定位中全局语义理解与局部动态感知割裂的核心难题,提出了创新的统一静态-动态建模框架(如图1所示)。该框架模拟人脑处理视频信息的双阶段过程:首先通过静态多模态信息关联实现语义互补(图2左),继而通过动态视觉感知机制沿时间线捕捉短期效应、相关性线索和感知复杂性三大特征(图3右),模型在ActivityNet基准测试中取得了75.85%的Top-1定位准确率(IoU=0.3)。如图3所示,UniSDNet-M模型在保持卓越精度的同时,处理速度达到每秒可处理111 个查询,显著优于传统方法。
TPAMI在中国计算机学会认定的人工智能领域四个A类期刊中排名第一,是计算机视觉及模式识别领域最顶尖的期刊,属于中国科学院SCI 1区TOP期刊。根据Google Scholar Citation统计,TPAMI在所有计算机工程、电子工程及人工智能相关期刊榜单上h5-index指数排在第一位,主要收录人工智能、模式识别、计算机视觉及机器学习领域的原创性科研成果。
情感计算与先进智能机器安徽省重点实验室
2025年9月19日
 安徽省合肥市蜀山区丹霞路485号(合肥工业大学翡翠湖校区)
安徽省合肥市蜀山区丹霞路485号(合肥工业大学翡翠湖校区) aflab_hfut@163.com
aflab_hfut@163.com