



 科研动态
科研动态 2025-08-24
2025-08-24
实验室3篇论文被ICCV 接收。ICCV 是全球计算机视觉领域最具影响力的顶级学术盛会,与 CVPR 和 ECCV 并称“计算机视觉三大顶会”。ICCV 在学术界与产业界均占据核心地位,且被中国计算机学会(CCF)评定为A 类会议。
被录用的论文列表如下:
1. Towards Complete Scene and Regular Shape for Distortion Rectification by Curve-Aware Extrapolation (Kang Liao, Chunyu Lin, Yunchao Wei, Feng Li, Shangrong Yang, Yao Zhao)
2. SMoLoRA: Exploring and Defying Dual Catastrophic Forgetting in Continual Visual Instruction Tuning (Ziqi Wang, Chang Che, Cheems Wang, Yangyang Li, Zenglin Shi, Meng Wang)
3. Visual-Oriented Fine-Grained Knowledge Editing for MultiModal Large Language Models (Zhen Zeng, Leijiang Gu, Xun Yang, Zhangling Duan, Zenglin Shi, Meng Wang)
重点介绍其中一篇主题为视觉指令微调的论文:
随着多模态大模型在视觉语言理解层面展现的强大能力,如何在不断适应新任务的同时稳健保留已有知识,成为持续视觉指令微调(CVIT)领域亟需解决的难题。现有方法多沿用传统连续学习范式,忽视了CVIT特有的“双重遗忘”现象——既遗忘视觉理解,又削弱指令遵循能力。对此,我们提出SMoLoRA框架,通过可分离的LoRA路由机制,分别优化视觉理解与指令遵循两条路径,在提升泛化能力的同时,有效缓解双重遗忘。此外,我们构建更具挑战性的基准体系,系统评估模型在多样任务与指令下的稳健性与泛化表现。
近日,国际计算机视觉大会(International Conference on Computer Vision, ICCV)公布了论文录用结果,本实验室博士生王子奇的研究论文“ SMoLoRA: Exploring and Defying Dual Catastrophic Forgetting in Continual Visual Instruction Tuning”被成功收录。该项成果王子奇为第一作者,本实验室时增林教授为通讯作者,由我院联合清华大学,网络空间研究院共同完成。
论文简介:
论文标题:
SMoLoRA: Exploring and Defying Dual Catastrophic Forgetting in Continual Visual Instruction Tuning
论文作者:
Ziqi Wang, Chang Che, Cheems Wang, Yangyang Li, Zenglin Shi, Meng Wang
论文链接:
https://arxiv.org/pdf/2411.13949
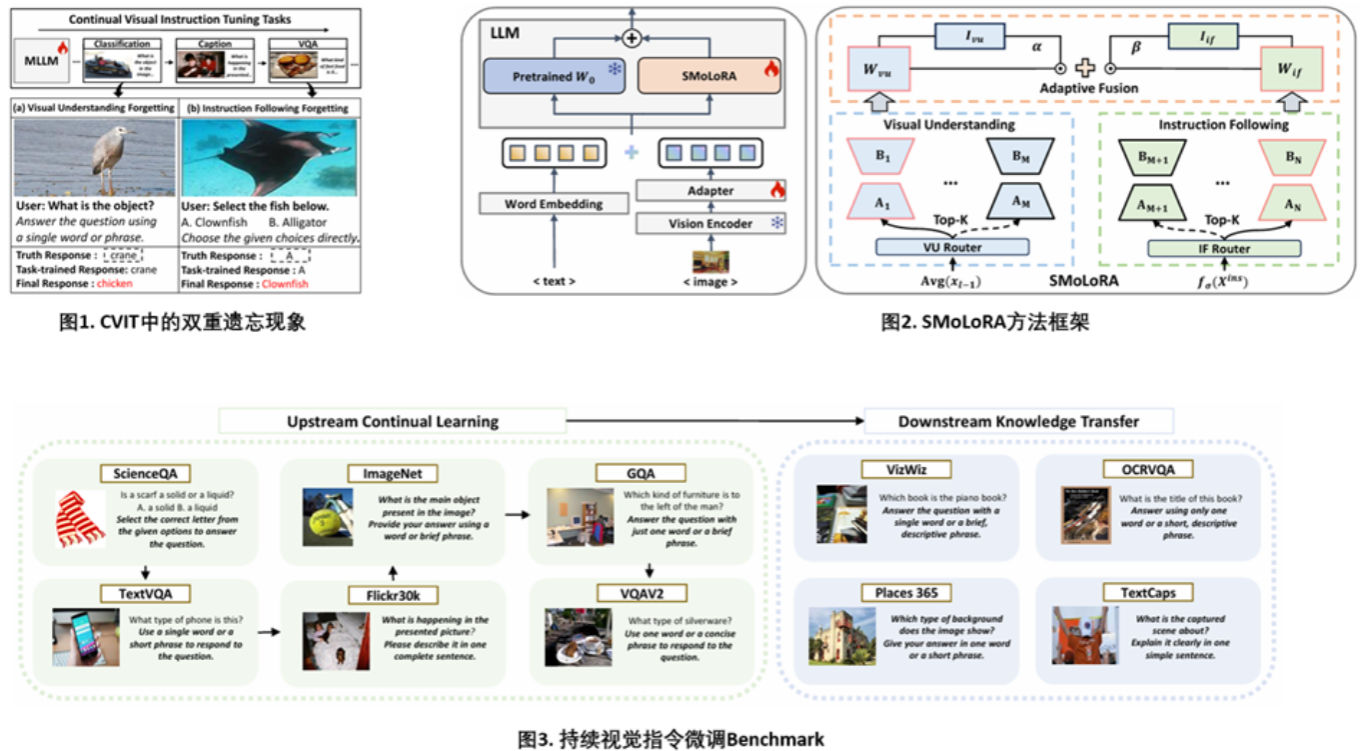
视觉指令微调通过将各类视觉任务统一转化为语言指令,使多模态大语言模型具备通用的视觉任务处理能力。在此基础上,持续视觉指令微调进一步扩展了MLLMs的能力,使其能够不断增量学习新任务,适应不断变化的需求。然而,已有研究尽管提出了新的基准与方法以缓解灾难性遗忘,但大多沿袭传统持续学习范式,忽视了CVIT所特有的挑战。我们发现CVIT中存在双重灾难性遗忘现象:模型在学习新任务时不仅遗忘已有的视觉理解能力,同时其指令遵循能力也会持续退化。为此,我们提出可分离低秩适应混合框架,通过引入视觉理解与指令遵循两个独立模块,实现可分离路由,分别专注于各自领域的适应与优化,从而有效避免遗忘并提升性能。此外,我们构建了新的CVIT基准,较现有工作进一步考察模型对未见任务的泛化能力与多样化指令的鲁棒性。大量实验证明,SMoLoRA在缓解双重遗忘、提升对新任务的泛化与稳健指令遵循方面,均优于现有方法。
情感计算与先进智能机器安徽省重点实验室
2025年8月24日
 安徽省合肥市蜀山区丹霞路485号(合肥工业大学翡翠湖校区)
安徽省合肥市蜀山区丹霞路485号(合肥工业大学翡翠湖校区) aflab_hfut@163.com
aflab_hfut@163.com