



 科研动态
科研动态 2024-12-27
2024-12-27
2024年12月10日,实验室8篇论文被AAAI 2025接收。AAAI全称是AAAI Conference on Artificial Intelligence,是人工智能领域的顶级国际会议。会议将于2025年2月25日至3月4日在美国费城召开。中稿论文简介如下:
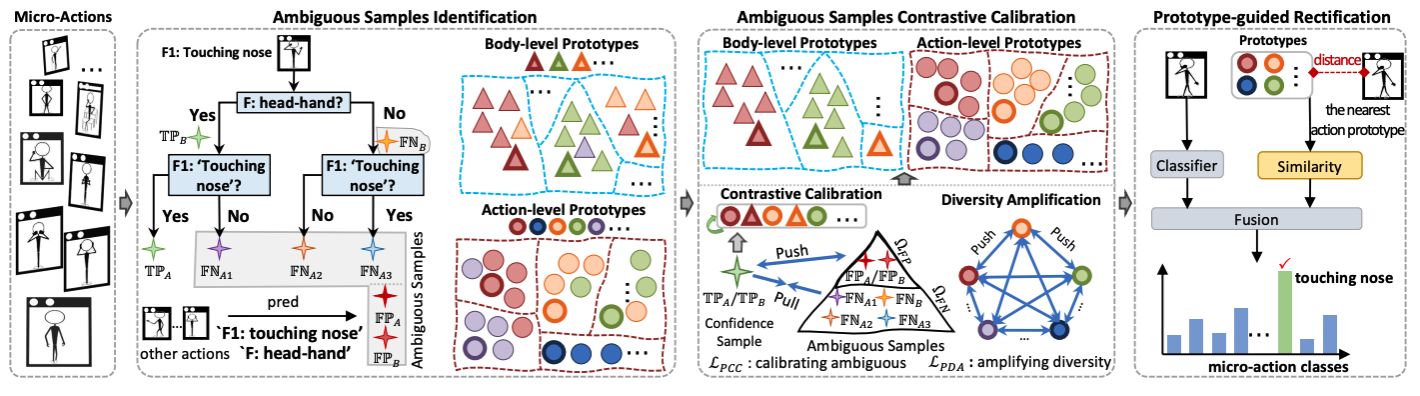
1)Prototypical Calibrating Ambiguous Samples for Micro-Action Recognition
Kun Li, Dan Guo*, Guoliang Chen*, Chunxiao Fan, Jingyuan Xu, Zhiliang Wu, Hehe Fan, Meng Wang
文章面向微动作识别任务(Micro-Action Recognition, MAR),研究基于原型学习与对比校准的思想,提出了一种原型校准模糊网络(Prototypical Calibrating Ambiguous Network, PCAN),旨在解决微动作类别间的模糊性问题。首先,PCAN 采用层次化动作树(Hierarchical Action-Tree)对微动作进行模糊样本识别,将误分类样本划分为假阴性(False Negative, FN)和假阳性(False Positive, FP)两类。随后,引入模糊对比校准模块(Ambiguous Contrastive Refinement Module),通过调节模糊样本与对应类别原型之间的距离,使 FN 样本更接近其正确类别原型,同时推动 FP 样本远离错误类别原型。此外,PCAN 还设计了一种原型多样性增强损失(Prototypical Diversity Amplification Loss),提高模型对不同类别的区分能力,并结合原型引导修正模块(Prototype-Guided Rectification)进一步优化分类决策。在MA-52 基准数据集上的实验结果表明,PCAN 在多个评测指标上均优于现有方法,特别是在难分类的微动作类别上取得了显著提升,提高了微动作识别的准确性和鲁棒性。
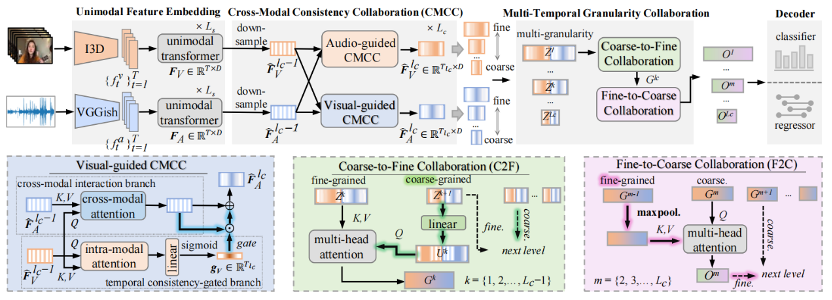
2)Dense Audio-Visual Event Localization under Cross-Modal Consistency and Multi-Temporal Granularity Collaboration
Ziheng Zhou, Jinxing Zhou, Wei Qian, Shengeng Tang, Xiaojun Chang, Dan Guo*
在视听学习领域,目前大多数研究任务都只关注精细修剪的短视频。本文重点关注更实用的密集视听事件定位 (DAVEL) 任务,以推进对较长、未剪辑视频的视听场景理解。此任务旨在识别并精确定位音频和视频流中同时发生的所有事件。通常,每个视频包含多个类别的密集事件,这些事件可能在时间线上重叠,且每个事件的持续时间各不相同。为了应对这些挑战,本文设计了一种新颖的 CCNet,它包含两个核心模块:跨模态一致性协作 (CMCC) 和多时间粒度协作(MTGC) 。CMCC 模块包含两个分支:跨模态交互分支和时间一致性门控分支。前一个分支通过编码视听关系促进跨模态的一致事件语义的聚合,而后一个分支则引导一种模态的焦点转移到另一种模态中辨别出的关键事件相关时间区域。MTGC 模块包括一个由粗到细的协作块和一个由细到粗的协作块,在粗粒度和细粒度时间特征之间提供双向交互。在 UnAV-100 数据集上进行的大量实验验证了所提出的模块设计,证明CCNet在密集的视听事件定位任务中实现了新的最先进的性能。
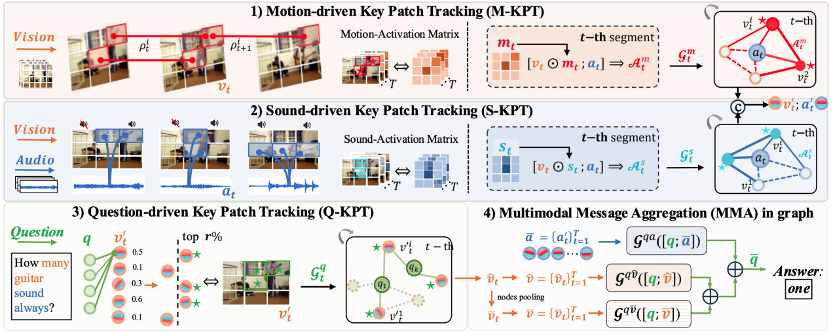
3)Patch-level Sounding Object Tracking for Audio-Visual Question Answering
Zhangbin Li, Jinxing Zhou, Jing Zhang, Shengeng Tang, Kun Li, Dan Guo*
针对视听问答(AVQA)任务中发声物体运动捕捉和跟踪的难题,本文首创基于补丁级联追踪的PSOT方法。该框架构建三重协同机制:1)运动驱动模块(M-KPT)通过帧间运动强度图构建动态图网络,捕捉显著运动区域;2)声源驱动模块(S-KPT)利用跨模态音视对应图强化发声区域定位;3)问题驱动模块(Q-KPT)实施语义注意力筛选,聚焦问答相关特征。三模块通过并行-串联混合架构实现运动显著性、声源关联性、问题指向性的动态平衡,采用跨模态图注意力机制(运动+声源双重增强化)实现多模态特征协同更新,最终通过层次化特征聚合完成答案推理。实验表明,本方法在标准数据集上较传统模型准确率显著提升,且较基于大规模预训练的方法推理效率表现更优,验证了细粒度时空建模在复杂AVQA任务中的有效性。
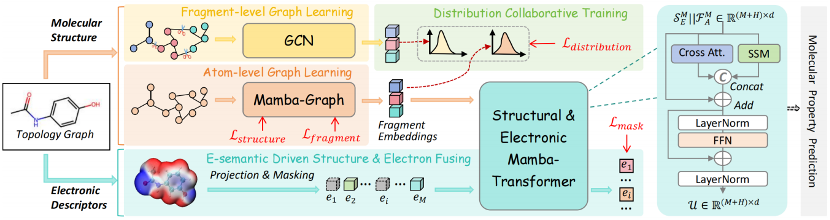
4)MOL-Mamba: Enhancing Molecular Representation with Structural & Electronic Insights
Jingjing Hu, Dan Guo*, Zhan Si, Deguang Liu, Yunfeng Diao, Jing Zhang, Jinxing Zhou, Meng Wang*
分子表示学习在 分子性质预测、药物设计、材料科学 等领域至关重要。然而,现有方法主要依赖 图神经网络(GNNs)或Graph Transformer(GTs)进行结构建模,往往忽略了分子结构与电子信息的耦合关系,导致分子表示不完整。针对这一问题,本文提出MOL-Mamba,结合Mamba状态空间模型(SSM),增强对分子结构和电子信息的建模能力。 MOL-Mamba 由Mamba-Graph(MG)进行分子结构的层次化推理,并通过Mamba-Transformer(MT)融合分子结构与电子相关性,同时提出结构分布协同训练和电子语义融合训练机制,以优化表征学习。实验表明,MOL-Mamba 在11个分子化学数据集上均超越当前SOTA方法,尤其在 BBBP、ESOL等任务上取得最佳ROC-AUC和最低RMSE,为分子表示学习提供了一种高效的新范式。
 安徽省合肥市蜀山区丹霞路485号(合肥工业大学翡翠湖校区)
安徽省合肥市蜀山区丹霞路485号(合肥工业大学翡翠湖校区) aflab_hfut@163.com
aflab_hfut@163.com