



 科研动态
科研动态 2026-05-30
2026-05-30
随着多模态大语言模型在复杂视觉理解任务中的广泛应用,如何让模型在持续学习新任务的同时保持既有能力,成为人工智能领域的重要挑战。传统持续视觉指令微调方法往往面临灾难性遗忘问题,即模型在适应新任务后,对先前任务的性能显著下降。现有结构扩展方法虽然能够在一定程度上缓解任务间干扰,但通常需要为每个任务扩展整层模块,带来较大的参数开销,难以兼顾性能与可扩展性。
近日,本重点实验室联合阿姆斯特丹大学,清华大学围绕持续视觉指令微调中的高效架构扩展问题开展研究,提出参数高效的持续学习新框架 LoRA in LoRA(LiLoRA)。显著压缩新增参数量的同时引入稳定性正则项约束共享表征的一致性,从而有效缓解持续学习中的灾难性遗忘问题。文章被人工智能顶会AAAI 2026录用为 oral presentation文章,第一作者为本实验室2024级硕博生车畅,通讯作者为时增林教授。
论文简介:
论文标题:LoRA in LoRA: Towards Parameter-Efficient Architecture Expansion for Continual Visual Instruction Tuning
论文作者:Chang Che , Ziqi Wang, Pengwan Yang*, Cheems Wang, Hui Ma, Zenglin Shi*
论文链接:
https://ojs.aaai.org/index.php/AAAI/article/view/39082
代码链接:
https://github.com/chanceche/LiLoRA
论文概述:
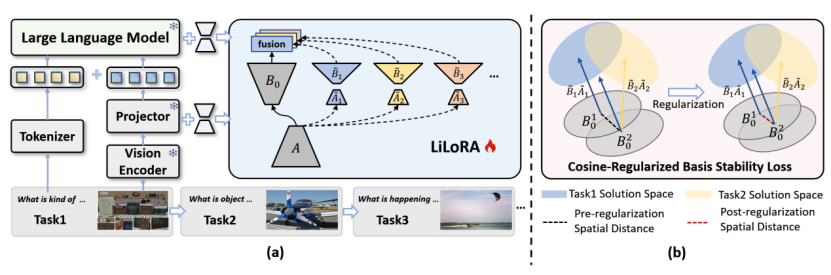
图1:LiLoRA 结构图
持续视觉指令微调使多模态大语言模型能够随着时间的推移逐步学习新的任务。然而,这一过程面临灾难性遗忘的挑战,即模型在适应新任务时,其在先前任务上的性能会显著下降。一种常见的缓解遗忘的方法是结构扩展,即为每个任务引入特定的模块以减少任务间的干扰。然而,现有方法通常为每个任务扩展整个层,这导致参数开销巨大、可扩展性差等问题。为了解决这些问题,研究提出了 LoRA in LoRA(LiLoRA),一种专为 MLLM 中的 CVIT 设计的高效架构扩展方法。LiLoRA 通过在任务间共享 LoRA 矩阵A来减少冗余,对矩阵B进行额外的低秩分解以最小化任务特定参数,并引入基于余弦相似度的稳定性正则项,以在时间维度上保持共享表示的一致性。在多样化的 CVIT 基准上进行的大量实验表明,LiLoRA 在持续的任务学习中表现出显著优于现有方法的性能,同时在参数效率方面也有大幅提升。
AAAI 是人工智能领域顶级国际学术会议(CCF-A 类)。本届AAAI 2026共收到 30,948份总投稿;其中主会技术论文轨道共有23,680篇投稿进入评审流程,最终4,167篇被接收,录用率为17.6%;其中 oral presentation 约占主会投稿的4.48%,充分体现了入选论文较高的学术水平和国际认可度。
情感计算与先进智能机器安徽省重点实验室
2026年5月30日
 安徽省合肥市蜀山区丹霞路485号(合肥工业大学翡翠湖校区)
安徽省合肥市蜀山区丹霞路485号(合肥工业大学翡翠湖校区) aflab_hfut@163.com
aflab_hfut@163.com