



 科研动态
科研动态 2026-01-30
2026-01-30
近日,国际万维网大会(The Web Conference,简称WWW 2026)论文录用结果公布。情感计算与先进智能机器安徽省重点实验室取得优异成绩,多篇高水平学术论文被大会录用,研究内容涵盖人工智能、数据挖掘、信息检索等前沿方向,充分展现了本实验室在相关领域的深厚科研积累与强劲的国际学术竞争力。
WWW会议是互联网与人工智能交叉领域历史最悠久、最具权威性的国际顶级学术会议之一,被中国计算机学会(CCF)推荐为A类会议。作为全球学者展示Web技术最新进展、探讨未来趋势的核心平台,其论文录用率长期保持在低位,入选成果代表着全球范围内的高水准研究。
论文简介
论文1标题:
Mitigating Fine-tuning Bias: A Parameter-Efficient Debiasing Framework for Large Language Models
论文作者:
李秋雨(博士生)、张琨、吴乐、刘昊、许鹤飞、李鑫、魏思
通讯作者:张琨
论文概述:
参数高效微调(PEFT)能够利用有限的领域数据将大语言模型(LLMs)适配到下游场景。然而,领域数据往往来源于开放网络或人工标注,不可避免地包含社会刻板印象或虚假统计关联等偏差,使得数据的输入特征与输出之间形成捷径连接(shortcut),造成PEFT模块在适配过程中对其过拟合,出现有偏微调并损害LLM的无偏性能。为此,我们提出一个通用的参数高效去偏框架PEDAL,针对领域数据有限的大模型高效适配场景,在不修改大多数模型参数的前提下,通过有选择性地修改样本并约束模型的输出,来缓解跨类型和数据域的多种偏差模式并保持任务性能。大量实验表明,PEDAL在消除多种偏差模式上达到了最佳性能。除此之外,PEDAL在任务性能上比BASE模型平均提升了7%-9%,并且与常规微调模型相比性能下降最小。
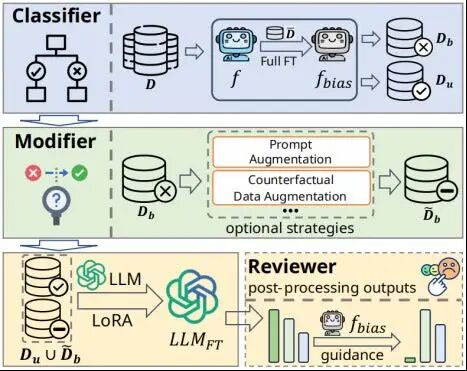
论文2标题:
Multistage Feedback-Driven Causal Discovery from Textual Datawith Large Language Models
论文作者:
杨俊涛(博士生)、曹大元、俞奎、汪祥、杨静、刘琳、李久永
通讯作者:俞奎
论文概述:
从非结构化文本中学习因果关系能显著增强决策能力与AI推理的鲁棒性。然而,现有因果发现方法主要面向结构化数值数据,难以直接用于文本;大语言模型虽具备语义理解能力,却难以从文本中挖掘多变量间复杂的因果关系。为此,本文提出一种多阶段反馈驱动的因果发现框架(CAST),其核心为自增强的因果发现流程:首先通过多轮随机采样与语义聚类提取低冗余、高共识的因果变量;接着基于学习到的变量,通过信息熵过滤机制将文本转化为高质量结构化数据;最后提出局部标签混乱因子(LLCF)概念,用于定位模型难以解释的样本,并以此驱动潜在因果变量的迭代发现与验证。该方法具备信息论基础与收敛性保证,在多个真实与合成数据集上的实验表明,CAST在因子提取准确率、结构化数据构建质量及因果图学习性能上均显著优于现有基线,尤其在资源受限场景下仍保持优异性能。本工作为从文本中端到端挖掘因果关系提供了系统方法,具有较强的实用价值与推广潜力。
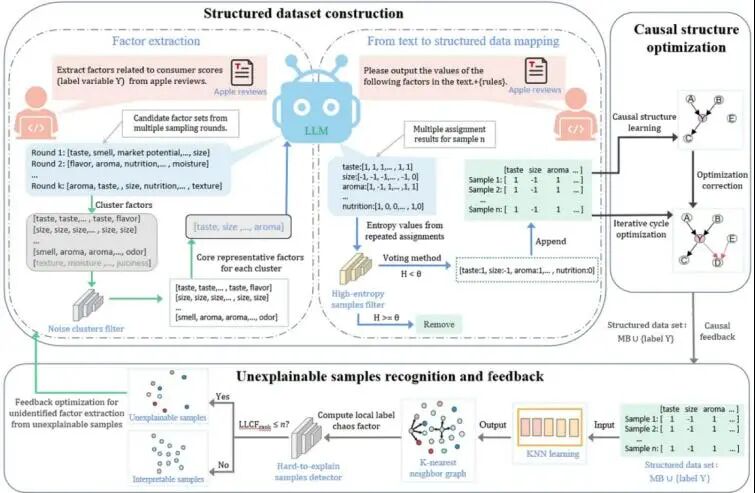
论文3标题:
WeaveRec: An LLM-Based Cross-Domain Sequential Recommendation Framework with Model Merging
论文作者:
侯旻、柳鑫、吴乐、何宸逸(本科生)、刘昊、李徵、李鑫、魏思
通讯作者:吴乐
论文概述:
跨域序列推荐系统通过迁移多域知识来提升目标域的推荐性能,现有方法大多依赖域间重叠用户或物品进行建模,这在实际场景中很难满足。大语言模型和模型融合技术为解决这一问题提供了很好的思路:LLM具备强大的语义理解能力,能够通过文本描述理解不同域的物品,摆脱对重叠用户或物品的依赖;而模型融合可以将各域独立训练的模型参数直接合并为单一模型,无需共享原始数据即可整合多域知识。然而实验发现,简单合并数据训练或直接融合多个领域模型反而会导致性能下降。针对这一问题,本文分析发现,源域模型未接触过目标域数据,在目标域上表现较差,而融合后的模型性能会被源域模型拉低。基于这一洞察,本文提出了WeaveRec框架,通过"交织"方式将源域与目标域数据混合训练多个LoRA模块,再进行模型融合。该方法无需重叠用户/物品、支持多源域扩展、且不增加推理开销。理论分析以及在多个品类的跨域和跨平台推荐实验表明,WeaveRec均显著优于现有基线方法。
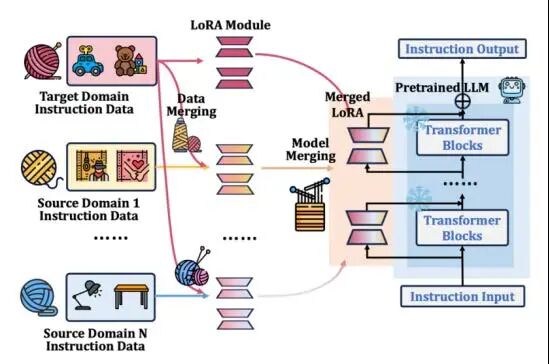
论文4标题:
VC-Soup: Value-Consistency Guided Multi-Value Alignment for Large Language Models
论文作者:
许鹤飞(博士生)、吴乐、汪宇、侯旻、武晗、张震、汪萌
通讯作者:吴乐
论文概述:
本文提出了一种基于价值一致性引导的多元价值观对齐框架VC-Soup,用于解决大型语言模型在同时对齐多种可能相互冲突的人类价值观(如有用性、安全性、诚实性)时面临的参数干扰与性能退化问题。针对现有多价值观对齐方法忽视样本层面价值观分歧、模型融合不稳定的局限,VC-Soup从数据层面出发,引入价值一致性度量指标,对多价值偏好数据进行一致性过滤,仅保留在多个价值维度上具有协同优化作用的样本,从而有效缓解跨价值梯度冲突。在此基础上,论文基于一致性数据分别训练价值一致性参数向量,并通过线性模型融合与帕累托排序,高效构建在多价值观维度上具有良好权衡关系的模型集合,无需为不同价值观组合重复训练模型。理论分析表明,该方法能够显著提升模型参数的线性模态连通性,为稳定的融合提供保障。实验显示,VC-Soup优于SOUP、MODPO 等主流方法,在多个数据集上取得了更优的价值观平衡。总体而言,VC-Soup 提供了一种高效、稳定且可扩展的多元价值观对齐方案,为以参数合并为核心的多值对齐研究指明了数据层面一致性的重要方向。
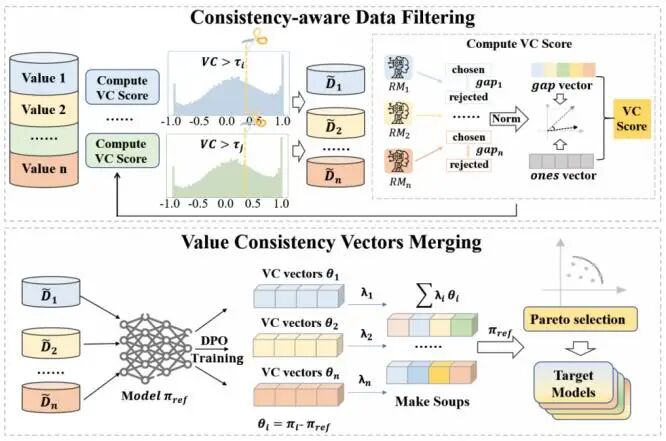
论文5标题:
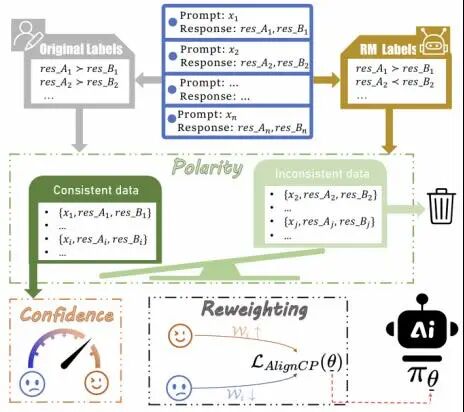
AlignCP: Noise-Aware Preference Alignment for LLMs via Confidence and Polarity Reweighting
论文作者:
程晨(硕士生)、许鹤飞、吴乐
通讯作者:吴乐
论文概述:
本文提出了一种轻量且可解释的数据感知偏好对齐框架AlignCP,用于缓解偏好对数据中噪声(如标签翻转、不一致评判)对DPO/偏好优化训练带来的负面影响。通过对Anthropic-HH等数据集的实证分析,本文发现约25%的偏好对在奖励模型判断与人工标注间存在明显不一致,这类样本往往无法提供有效训练信号,甚至会降级模型行为。基于此,AlignCP从奖励模型输出中构造了两个可解释信号:Confidence,用于衡量偏好判决的置信度;Polarity,用于刻画奖励排序方向与人工标注的一致性。基于二者联合设计样本权重,对高置信且方向一致的偏好对进行强化学习,对低置信或方向冲突样本进行抑制,从而在无需重标注数据的情况下有效过滤噪声干扰。实验结果表明,AlignCP在Anthropic-HH等基准数据集上显著优于DPO及其多种变体,在帮助性与安全性等指标上均取得稳定提升,且在标签翻转等噪声场景下表现出更强的鲁棒性。总体而言,AlignCP提供了一种自动化、可解释且高效的偏好数据质量控制与重权策略,为稳健地提升LLM偏好对齐性能提供了实用方案。
论文6标题:
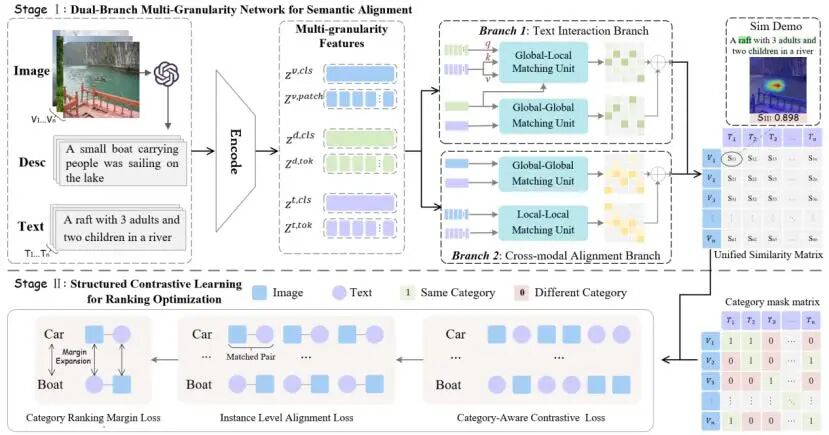
Dual-Branch Multi-Granularity Network with Structured Contrastive Ranking for Cross-Modal Retrieval
论文作者:
陈子毫(博士生)、卜晨阳、嵇圣硙、吴信东
通讯作者:吴信东
论文概述:
随着多模态检索增强生成(Multimodal RAG)系统的快速发展,如何从大规模图像与文本数据中准确检索与用户查询高度相关的跨模态证据,已成为支撑多模态推理与生成的重要基础。然而,现有跨模态检索方法多依赖共享嵌入空间进行图像与文本对齐,在真实场景中仍受到语义稀疏与排序不稳定两方面的制约:判别性语义往往仅分布于图像的局部区域或文本的少量词元中,而语义相近的候选样本之间易产生排序混淆。为此,本文提出一种双分支多粒度跨模态检索框架DBMG,通过语义增强与结构化排序优化协同提升检索性能。该方法引入多模态大模型(MLLM)显式揭示图像中隐含且难以由局部特征直接感知的判别性语义,并通过双分支结构联合建模全局与局部层面的跨模态对应关系。在此基础上,引入结构化对比排序学习,从类别与实例层面约束检索结果的排序一致性。实验结果表明,所提出的方法在多个标准跨模态检索数据集上显著优于现有方法,并在低资源场景下表现出良好的泛化能力。
情感计算与先进智能机器安徽省重点实验室
2026年1月30日
 安徽省合肥市蜀山区丹霞路485号(合肥工业大学翡翠湖校区)
安徽省合肥市蜀山区丹霞路485号(合肥工业大学翡翠湖校区) aflab_hfut@163.com
aflab_hfut@163.com